
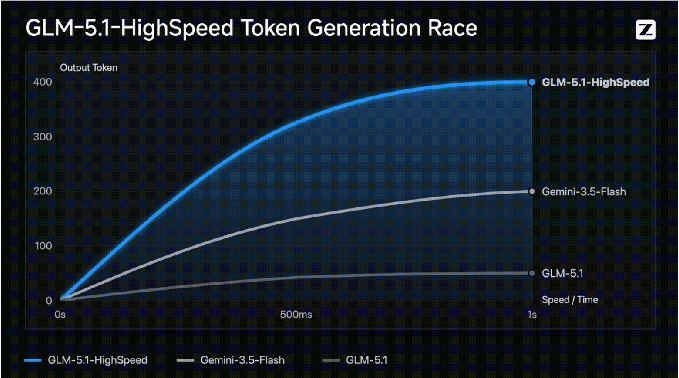
GLM-5.1高速版API刷新400tokens/s纪录
「智谱联合TileRT推出GLM-5.1高速版API,实现400tokens/s推理速度,打破高性能与低延迟不可兼得的行业惯例。」
智谱今日正式面向部分企业客户推出GLM-5.1高速版API,该版本在保持旗舰级模型能力的同时,实现了高达400tokens/s的稳定推理速度,刷新了国产大模型在实时交互场景下的性能纪录。这一突破打破了行业过去“高性能模型必然带来高延迟”或“高速模型只能是轻量级模型”的惯例,首次在国产大模型中将旗舰级模型能力与极致低延迟同时带入生产环境,用户无需再为响应速度而牺牲模型质量。
在长程任务和复杂生产环境中,速度的提升带来了产品形态的质变。在AI编程场景中,GLM-5.1高速版在完整保留GLM-5.1强大能力的基础上,实现“即问即答”。模型能一边理解工程上下文,一边持续生成代码与修改方案。在需要数十轮调用的重构项目中,彻底消除了累计数分钟的空等。在实时动态建模方面,3D地图实测显示,玩家控制角色移动并输入文字后,模型能够瞬时完成建模并实时改变场景,带来沉浸式交互体验。此外,在Agent Swarm并行调度中,模型可在30秒内完成复杂网页处理,并能瞬间调度50个不同人格并行回答,展现出新型操作系统的雏形。
400TPS的稳定生产级能力,得益于智谱GLM团队与TileRT团队联合进行的系统级优化。在推理引擎层,TileRT采用编译期AOT静态编排技术,彻底抛弃了Runtime层的动态调度。传统主流框架以算子作为基本调度单元,在单token、小batch场景下会放大调度、访存与同步开销。TileRT在编译期将整个计算图静态编排为一个常驻GPU的Persistent Engine Kernel,在单卡内,计算、异步IO与通信被拆解为Tile级微任务,整个推理只Launch一次Kernel,中间结果通过寄存器、Shared Memory和L2Cache直传,不再写回全局内存,大幅降低了延迟。在调度系统层,通过动态批处理、请求合并和KV缓存调度优化,显著降低了高并发场景下的尾延迟。在基础设施层,TileRT将SM内部的Warp Specialization思路扩展到整张8卡NVL拓扑,不同GPU rank依据计算密度与数据依赖被特化为不同worker,配合网络链路与负载均衡协同优化,确保高性能的常驻稳定性。
GLM-5.1高速版适用于对响应延迟要求极高的AI编程、实时交互、商业决策以及实时语音等场景。目前该服务已正式上线,为企业用户提供了从模型能力到推理速度的全面升级方案。
来源:Heooo AI工具导航