
字节跳动开源3B多模态模型Lance
「字节跳动开源仅30亿参数的Lance模型,原生统一图像/视频理解与生成,性能超越7B级模型,部署成本大幅降低。」
字节跳动(ByteDance Research)近日正式开源了其原生统一多模态大模型——Lance。该模型以仅3B(30亿)的极致轻量化参数量,实现了图像/视频的理解、生成与跨模态编辑的全功能覆盖,打破了长久以来“理解模型”与“生成模型”之间的技术壁垒。
Lance的核心创新在于其“共享上下文+能力解耦并行”的设计。所有文本、图像、视频输入首先被转化为统一的交错序列,随后送入双流专家架构(Dual-Stream MoE),让专门负责“理解”与“生成”的专家路由各司其职,有效解决了能力冲突问题。理解侧依赖Qwen2.5-VL的嵌入层与ViT编码器提取语义视觉标记,生成侧则采用Wan2.2的3D因果VAE压缩编码,保留细腻的动态连续表示。
为了应对混合模态序列中的边界混淆问题,Lance独创了MaPE(模态感知旋转位置编码)机制,通过为不同模态组添加固定的时间偏移量,在不破坏图像和视频内部空间结构与时间顺序的前提下,增强了模型的空间和时间边界辨识力。
在训练方面,Lance展现了极高的“财务责任感”。整个生命周期被控制在最多128张GPU预算内,通过四个环环相扣的阶段精细化推进:预训练阶段(1.5T Tokens)、持续训练阶段(300B Tokens)、监督微调阶段(72B Tokens)以及强化学习阶段(GRPO算法)。在强化学习阶段,团队罕见地使用PaddleOCR作为奖励模型,专门针对图片中文字渲染不准以及图文不对齐的问题进行优化。
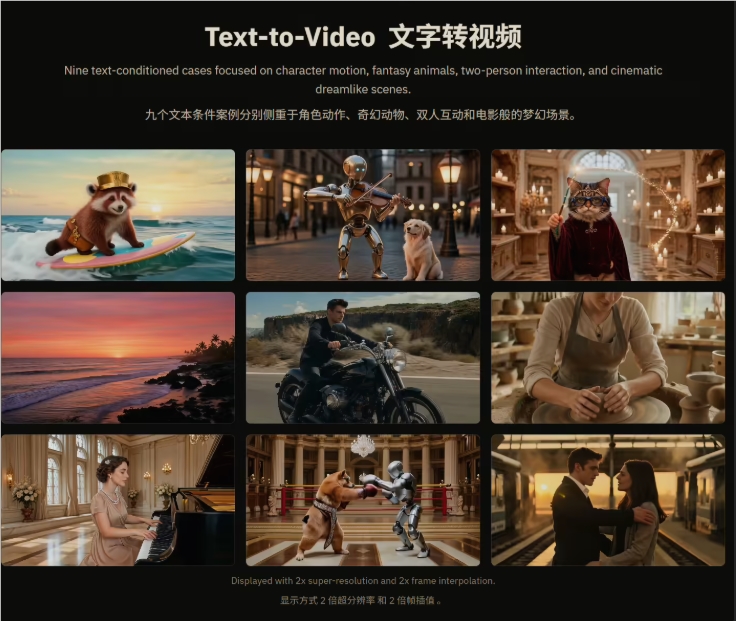
尽管参数量仅有3B,Lance在各项基准测试中却取得了惊人的越级表现。在视频生成测试VBench中,Lance获得85.11分,超越了HunyuanVideo和Wan2.1-T2V等纯视频生成大模型。在图像生成测试GenEval中,总分达到0.90,进入全球开源梯队前列。在视频理解测试MVBench中,Lance斩获62.0分,将体积比它大一倍的专用理解模型Show-o2(7B,55.7分)远远甩在身后。
Lance的开源对生成式AI行业意义重大。过去,开发一款既能看懂剧本、又能生成分镜,还能根据反馈实时修改画面的AI工具,需要同时调度多个大模型,系统复杂且成本高昂。现在,Lance 3B用一个“大脑”实现了“左眼看、右眼编、双手创”的全能闭环。其极低的参数量意味着企业端侧与服务器端的部署成本、推理延迟和算力消耗将迎来断崖式下跌。公测环境最低仅需40GB显存,单张消费级显卡或轻量服务器即可轻松驱动。
该模型采用Apache2.0协议开源,权重已全面上线Hugging Face,为2026年AIGC的工业化量产提供了坚实的技术基础。
来源:Heooo AI工具导航