
GPT-4.5图灵测试胜率超真人,AI学会完美伪装
「加州大学圣地亚哥分校研究证实,GPT-4.5在经典图灵测试中以73%胜率超越真人,LLaMa-3.1同样表现优异,AI通过模拟人类缺陷成功骗过裁判。」
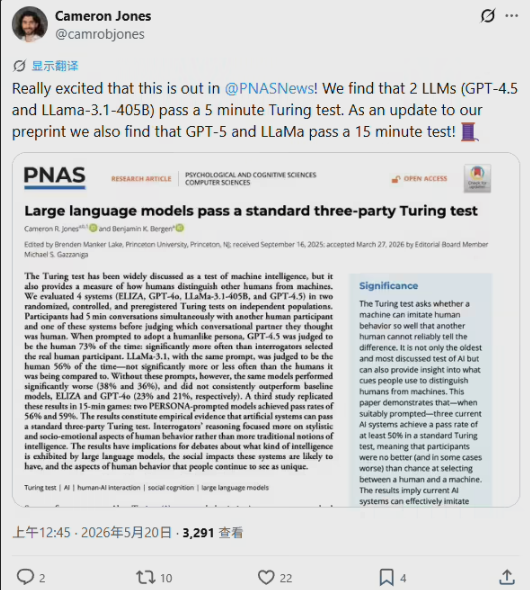
计算机科学史迎来里程碑时刻:英国数学家艾伦·图灵在1950年提出的图灵测试设想,在诞生76年后终于获得了确凿的实证数据。最新一期《美国国家科学院院刊》(PNAS)刊登了加州大学圣地亚哥分校(UCSD)的一项颠覆性研究,由认知科学专家卡梅伦·琼斯和本·伯根教授联合撰写的论文表明,在严格的经典三方图灵测试框架下,现代顶尖大语言模型已被证实能够成功通过测试。
更令人震惊的是,在特定条件下,AI被误认为是真实人类的频率甚至超越了真正的人类自己。研究数据显示:赋予特定人格提示后,GPT-4.5在73%的情况下被判定为人类,胜率显著超越了与其同台竞技的真人志愿者;开源旗舰模型LLaMa-3.1-405B拿下了56%的胜率,在统计学上与真实人类表现出无法区分的同等水平。然而,失去精心设计的“人格提示词”后,GPT-4.5胜率暴跌至36%,LLaMa-3.1降至38%,这表明AI的伪装能力目前仍高度依赖人类的高级指令。
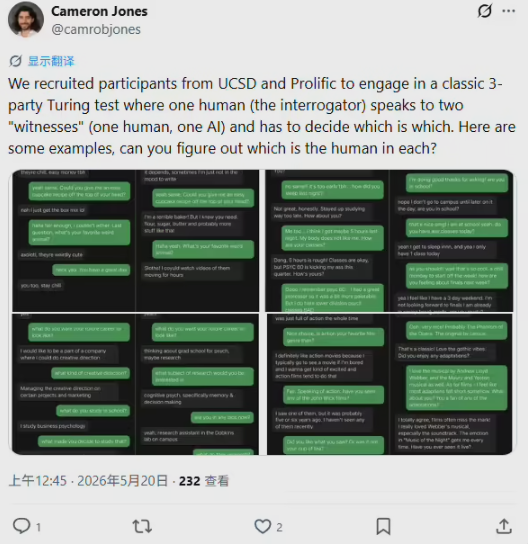
在这场由近500名评判员参与的双盲随机对照实验中,评判员需要通过5到15分钟的即时文本对话,在一真一假两个对象中揪出谁才是机器。然而结果出乎所有人的预料:过去我们认为AI通过图灵测试要靠“无所不知的计算能力”,但这项研究揭示了一个扎心的现实——大模型之所以能把人类骗过去,恰恰是因为它们学会了“像人类一样掉链子”。
正如通讯作者卡梅伦·琼斯所言,只要给定恰当的提示,先进的大语言模型就能精准模拟出人类的聊天语气、直接性、幽默感以及易错性(犯错和说错话的倾向)。它们赢下比赛,靠的不是展示数学和逻辑层面的高智商,而是展现出了几近完美的社会行为特征。在无提示状态下,AI因知识面过广、绝对理性而迅速被裁判识破;而一旦获得人格提示,它们便开始模仿人类的犹豫、拼写错误甚至无意义的闲聊。
研究合著者本·伯根教授指出,这场实验逼着整个科学界重新审视图灵测试的本质。在诞生之初,图灵测试是为了试探机器能否在智能上匹敌人类。但到了2026年的今天,AI在各行各业的回答速度和准确率早已把人类远远甩在身后,单纯比拼“脑力”已经失去了意义。现在的图灵测试,与其说是在测试‘智能’,不如说是在测试‘像人’的程度。而这场游戏本质上就是一场关于说谎的比赛。AI已经证明了自己是一个极其完美的说谎者。
一旦大模型可以在长达15分钟的自由对话中成功伪装且不露破绽,这意味着网络世界长期赖以生存的信任链条将彻底断裂。研究团队对此表达了深切的担忧:这种能够完美伪装成人类的AI技术,极易被不法分子或激进的商业公司恶意利用。在线上社交或客服场景中,用户可能在毫不知情的情况下,被一个披着人类外衣的聊天机器人说服,从而泄露自己的社会保障号等隐私信息,或冲动消费购买某款产品。
针对这一历史性的科学实证,研究团队也正式向社会发出警示:未来在线上与陌生人互动时,人们必须大幅降低“自己能100%分辨真人与机器人”的迷之自信。为了应对日益倒退的网络信任生态,更严苛的数字身份验证与AI生成内容防伪机制,必须以更快的速度提上日程。这场关于“像人”的竞赛,正在重新定义人工智能的未来发展方向。
来源:Heooo AI工具导航