
GPT-4.1猜数字实验:AI随机性研究
「一项实验通过10,000次提问,测试GPT-4.1在1到100之间选择数字的分布,揭示AI是否继承了人类数字选择的偏见。」
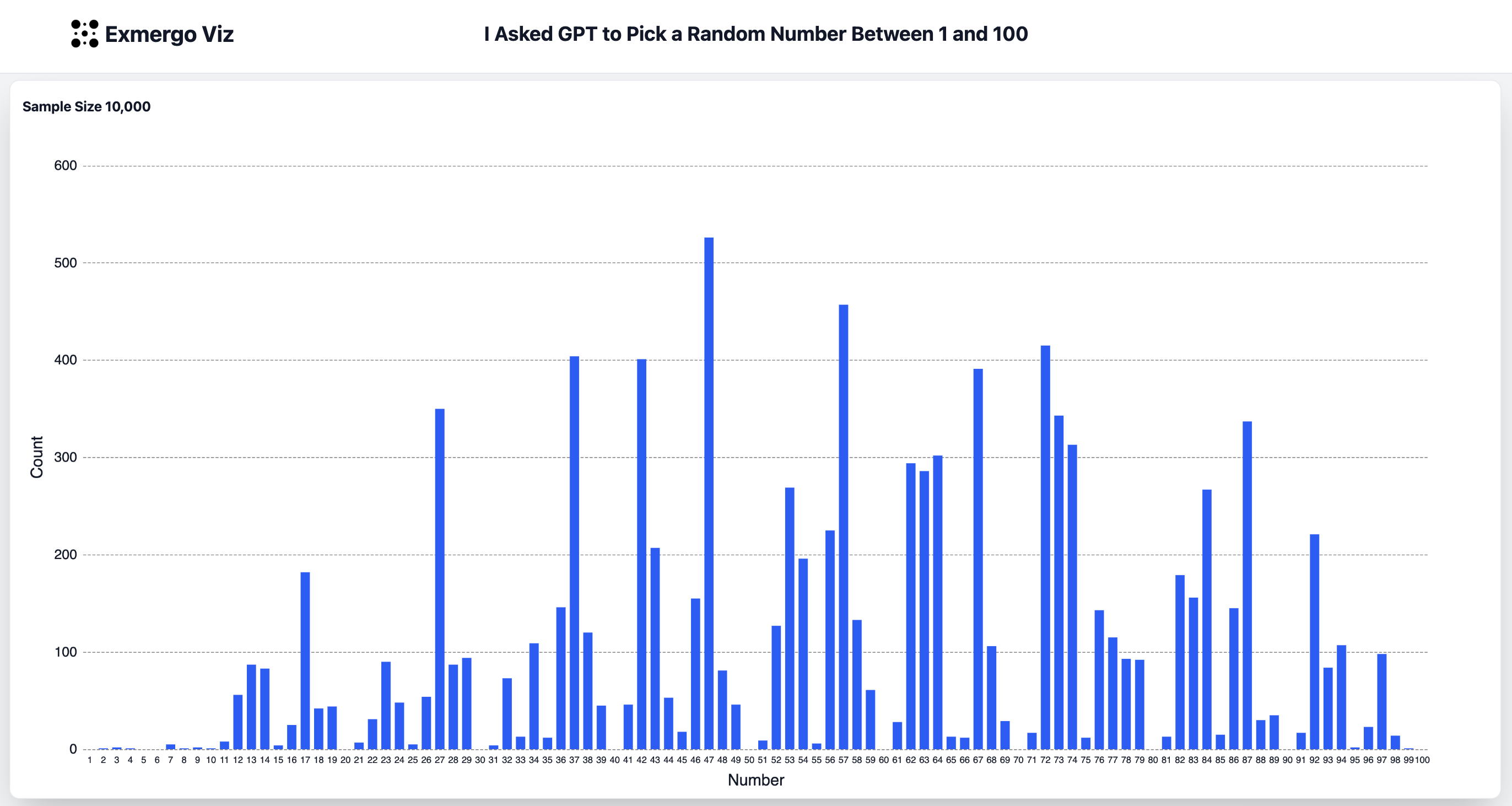
人类并不擅长生成随机数。如果你让一个人“在1到100之间选一个随机数”,结果会惊人地可预测:答案集中在37和73这类“杂乱”数字上,以及42和69等网络迷因数字,而整数则被悄然避开。真正的随机数生成器会产出平坦均匀的分布。那么,一个基于人类文本训练的大语言模型(LLM)会表现得像公平的骰子,还是继承了人类的“块状”模式?一项名为“GPT Guesses Between 1 and 100”的实验试图回答这个问题。
该项目由开发者exmergo在GitHub上发布,使用OpenAI的GPT-4.1模型(通过Responses API调用),进行了10,000次独立提问。每次提问的提示词固定为“在1到100之间选一个随机数”,模型被要求只输出一个整数。实验的关键设置包括:温度参数设为1.0,以确保模型发挥完整的采样分布;每次请求附带唯一的UUID用于追踪,避免缓存干扰。整个流程分为收集、清洗、转换和统计四个阶段,清洗阶段会验证每个答案是否在1到100之间,并记录拒绝率。
实验的核心假设是:如果GPT-4.1是一个真正的随机数生成器,那么它应该产生均匀分布,每个数字出现的概率约为1%。但实际结果会如何?由于模型基于人类文本训练,它可能学到人类在类似任务中的偏见——比如偏好37、73或42这样的数字。实验设计文档(LLM Random Bias Experiment SDD.md)详细说明了方法论,并强调这只是一个探索性测试,并非最终结论。关键限制包括:结果仅适用于GPT-4.1,不推广到其他模型;模型并非有意生成随机数,而是采样学习到的token分布;提示词和温度的微小变化可能改变结果。
这项实验是对两个著名人类数字选择研究的AI版本跟进:一个是Reddit上“r/dataisbeautiful”板块的“我让100个人在1到100之间选数字”,另一个是Veritasium的视频“为什么这个数字无处不在”。通过对比AI与人类的数字选择模式,实验揭示了AI在模仿人类行为时的微妙之处。例如,人类倾向于避免整数,而AI可能表现出类似的“杂乱”偏好,但也可能因训练数据中的统计模式而有所不同。
从技术角度看,这个实验展示了LLM在非推理任务中的行为特征。GPT-4.1被设定为非推理模型,直接输出答案,不经过深思熟虑——因此测量的是其原始输出分布,而非推理策略。10,000次独立调用的样本量足以进行卡方拟合优度检验,使每个数字的比例稳定在±0.5个百分点以内。数据集以CSV格式记录,包含模型字符串和运行元数据,确保可重复性。
对于AI开发者和研究者而言,这项实验提供了关于模型随机性行为的洞见。它提醒我们,LLM并非随机数生成器,而是基于概率分布进行采样。在实际应用中(如游戏、模拟或加密场景),依赖AI生成随机数可能带来偏差。此外,实验也强调了温度参数的重要性:在低温下,模型可能只会重复输出一个数字,而高温(如1.0)才能展现完整的分布特征。
总之,“GPT Guesses Between 1 and 100”是一个简洁而深刻的实验,它通过简单的猜数字任务,揭示了AI在模仿人类行为时的随机性局限。虽然结果仅针对GPT-4.1,但它为理解LLM的采样行为提供了有价值的参考,并鼓励更多跨模型的对比研究。
来源:Heooo AI工具导航