
MiniMax M3稀疏注意力架构突破百万Token效率
「MiniMax预告新一代大模型M3,采用稀疏注意力架构,Prefill与Decoding速度较前代提升近10倍与15倍,树立长上下文效率新标杆。」
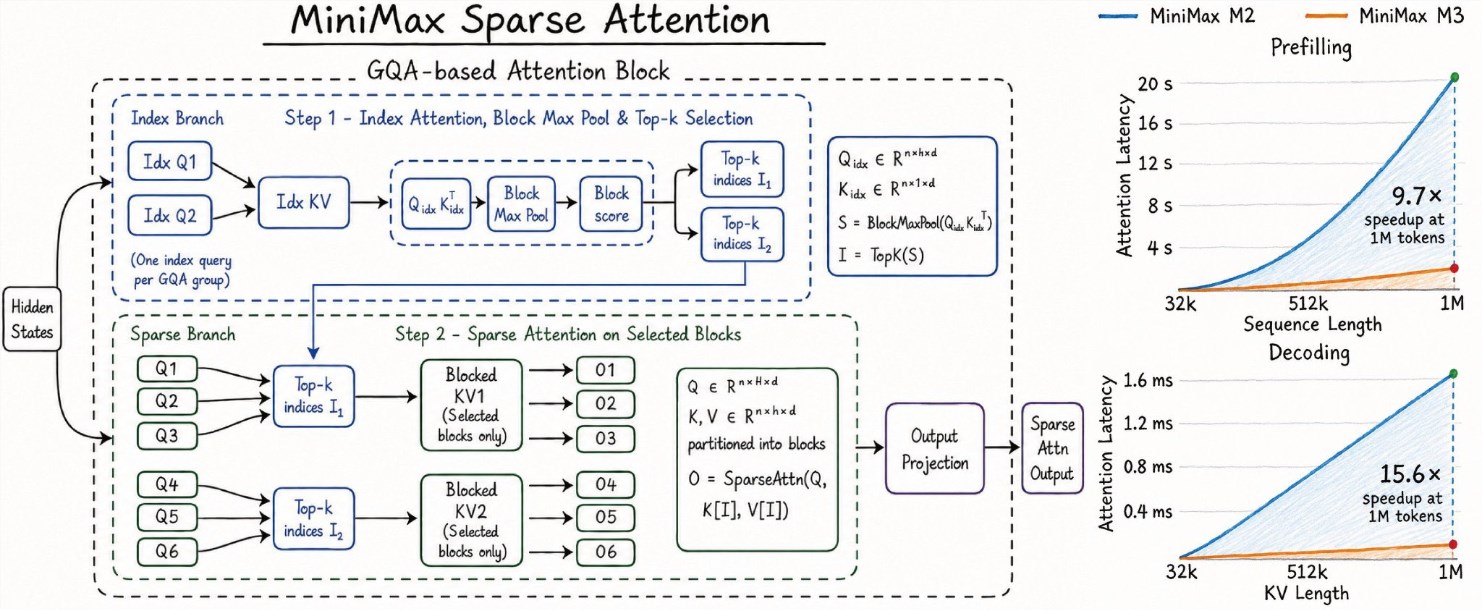
国内AI独角兽MiniMax即将发布新一代大模型M3,其AI工程负责人Skyler Miao近日在社交平台释放预告,称“Something BIG is coming!”,引发业界广泛关注。M3的核心创新在于采用全新的稀疏注意力(Sparse Attention)架构,通过Index Branch快速索引与Sparse Branch精准计算相结合的方式,有效解决了超长上下文场景下的计算瓶颈。
传统Transformer模型在处理百万Token级别上下文时,计算量会随序列长度呈平方级增长,导致推理成本高昂、响应延迟严重。而M3的稀疏设计能大幅降低这一开销,在保持高性能的同时实现显著的效率跃升,为长文本理解、长对话、多文档分析等应用场景提供有力支撑。这一技术突破意味着大模型在应对海量信息时,不再需要无限制地堆叠算力,而是通过算法创新实现“四两拨千斤”的效果。
对比前代M2(支持1M Token上下文),M3在关键指标上取得突破性提升:Prefill阶段速度提升9.7倍,Decoding阶段速度提升15.6倍。这意味着在实际部署中,M3能够以极低的算力成本高效处理超长上下文,显著降低推理成本,并为更复杂的AI应用打开想象空间。例如,在实时对话、代码补全、长文档摘要等场景中,用户将体验到近乎即时的响应,而企业也能以更低的成本提供高质量服务。
MiniMax此次M3的预告再次凸显了国内AI企业在架构创新上的竞争力。稀疏注意力等技术的突破,有望推动大模型从“参数规模竞赛”转向“效率与实用性竞赛”,为企业级落地和消费者应用带来更实惠、高效的体验。当前,业界对长上下文模型的需求日益迫切,从法律文档审查到科研论文分析,从客服历史追溯到代码仓库理解,百万Token级别的处理能力正成为刚需。M3的出现,或将重新定义这一领域的性能基准。
目前MiniMax尚未公布M3的具体发布时间与完整参数规模,但从工程负责人的预告及性能数据来看,这款模型有望成为长上下文处理领域的有力竞争者。随着稀疏注意力等架构创新的持续深化,大模型在效率与实用性上的平衡将变得更加灵活,推动AI技术向更广泛的应用场景渗透。
来源:Heooo AI工具导航