
技术进展
Stability AI发布Stable Audio 3,长音频秒级生成
Heooo 05月27日18时58分 31 阅读
「Stability AI推出Stable Audio 3音频大模型,支持可变长度生成与内补编辑,在消费级硬件上即可实现秒级长音频渲染。」
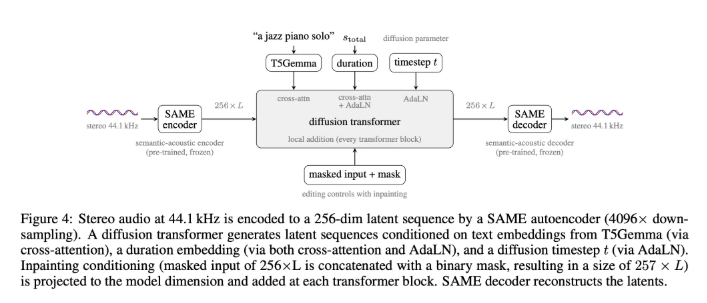
知名人工智能公司Stability AI近日正式发布了其最新一代音频大模型——Stable Audio 3。该模型家族涵盖了从小到大多种规格,能够满足音乐创作和音效制作等多元化需求。值得一提的是,该模型支持可变长度的音频生成,并引入了基于内补成像技术的音频编辑功能,为创作者提供了前所未有的灵活性。
创新架构打破了硬件限制。得益于高效的压缩机制,即使是在普通的消费级硬件上,该模型也能够流畅地运行长周期、大篇幅的音频生成任务。这不仅显著降低了高品质音频创作的技术门槛,也让个人创作者在家中开展专业级音视频制作成为可能。
超高效率实现了即时渲染。在variable-length技术的加持下,新模型的计算成本能够随着用户要求的音频时长动态缩放,彻底告别了以往固定长度带来的算力浪费。在高性能硬件的测试中,该模型仅需约0.62秒便可渲染出一段20秒的音频,而生成长达380秒的音乐也仅需1.31秒。此外,通过创新的三阶段训练流程,模型在保持高质量输出的同时,进一步优化了生成速度与资源占用。
Stable Audio 3的发布标志着AI音频生成技术迈入新阶段,为音乐人、音效设计师及内容创作者提供了强大而便捷的工具,有望推动音频创作领域的效率革命。
# Stability AI # Stable Audio 3 # 音频生成 # AI模型 # 内容创作
来源:Heooo AI工具导航