
英伟达开源Polar框架,Codex性能飙升594%
「英伟达发布开源AI框架Polar,通过GRPO训练方法使代码智能体Codex在SWE-Bench测试中性能提升近600%,训练效率提高5倍。」
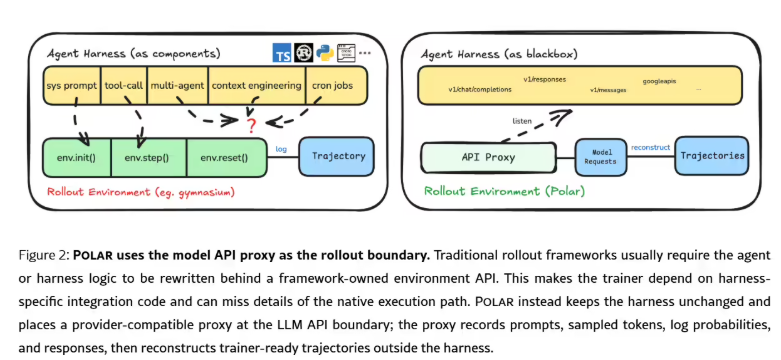
英伟达研究团队近日发布了一个全新的开源AI框架——Polar,旨在解决现有代码智能体框架在强化学习训练中的适配难题。该框架允许Codex、Claude Code、Qwen Code等智能体框架接入广义相对策略优化(GRPO)训练方法,而无需改变其原有的工具调用、上下文组织和补丁提交方式,为智能体性能提升开辟了新路径。
GRPO是一种针对强化学习的优化技术,通过奖励信号调整模型策略,帮助模型在多步决策任务中学习更优行为。在这项研究中,GRPO主要用于代码智能体的训练,让模型在实际的工具调用和补丁提交流程中不断改进表现。研究表明,智能体的强化学习正从单步任务转向更复杂的长流程任务,如代码仓库操作、浏览器交互和操作系统控制,这些任务依赖现有执行框架,涉及多轮调用和工具使用,直接改写为传统强化学习环境接口会导致关键训练信号丢失。
Polar框架的独特之处在于不重写智能体框架,而是在模型API边界处放置智能体,保持原有运行逻辑不变。它兼容多种请求风格,能记录关键数据并将其转化为训练信息。系统架构包括任务提交、会话调度和状态持久化等功能,通过优化初始化、运行和后处理流程,显著提升训练效率。实验结果显示,使用Polar与GRPO训练的智能体在SWE-Bench Verified测试中表现大幅提升,Codex的pass@1分数从3.8%跃升至26.4%,增长幅度达594.74%。
此外,该框架在效率方面同样出色,训练时间减少了约5.39倍,GPU平均利用率显著提升。这一突破为未来智能体训练提供了更强大的支持,表明开源社区在代码智能体强化学习领域迈出了重要一步。
来源:Heooo AI工具导航