自变量发布全球首个事件级具身智能世界模型
「自变量机器人团队发布WALL-WM世界模型,突破传统逐帧学习局限,以事件级预测革新机器人任务执行能力,实现泛化性能与三维感知的全面领先。」
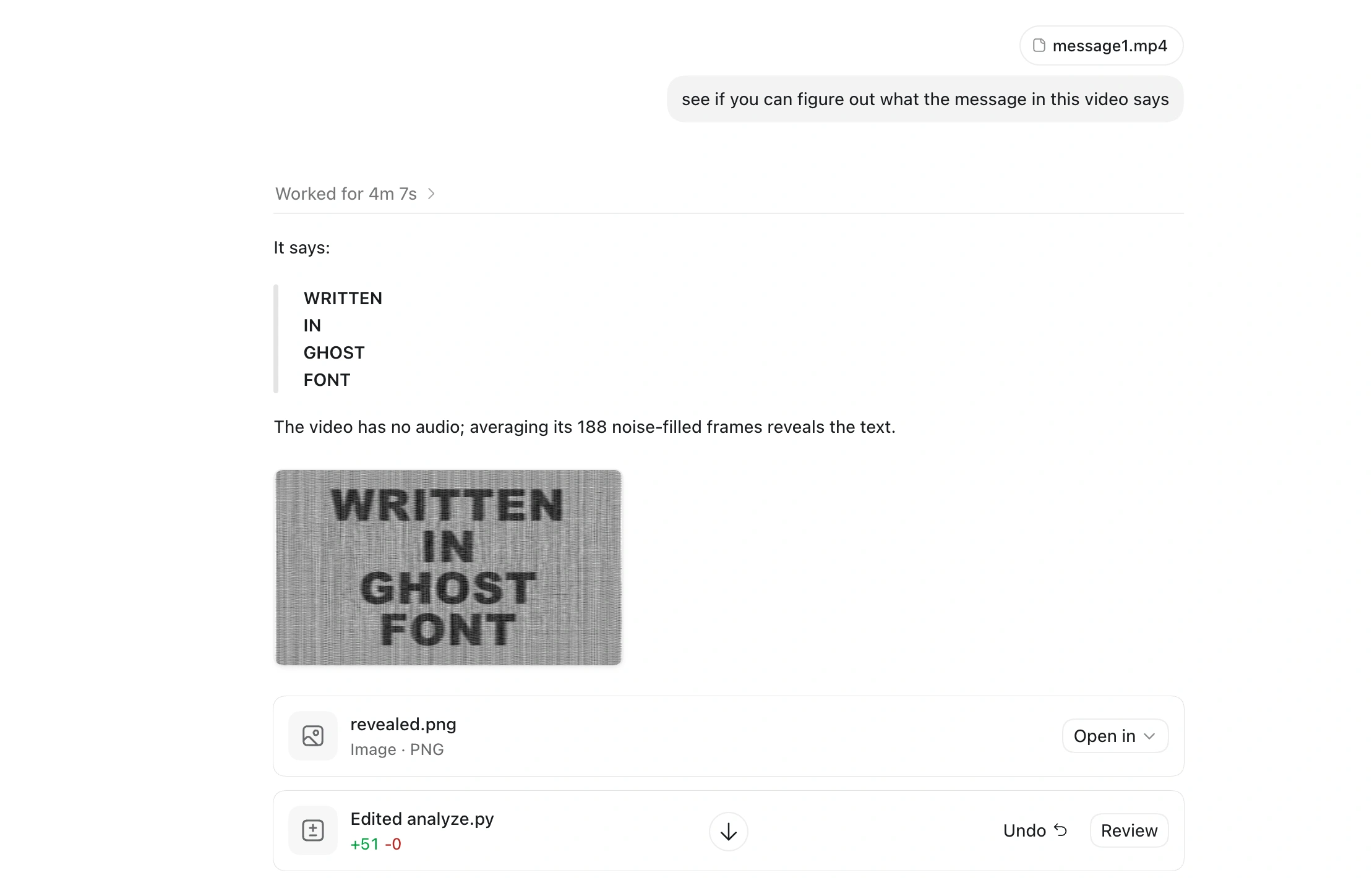
具身智能领域迎来里程碑式突破。5月29日,自变量机器人团队正式发布了全球首个基于“事件级预测”的具身智能世界模型WALL-WM。该模型打破了传统具身大模型按时间帧机械学习动作的局限,将世界模型的预测单位彻底切换为语义事件,标志着机器人理解与执行任务的能力迈向了全新阶段。
在当前的具身智能行业中,主流的视觉-语言-动作(VLA)模型普遍采用给定当前画面和指令、预测固定长度动作块的模式。这种逐帧填空式的笨拙训练方式,往往导致机器人只能记住微小的物理挪动,而忽略了动作的最终目标。一旦面对换杯子、换桌子等场景微调,机器人极易因缺乏泛化能力而“翻车”。为此,自变量团队在相关学术论文中指出,文本、视觉与动作三类信息在真实世界中天然存在不同的时间尺度和流形几何,强行在单一共享空间内对齐很容易损害预训练的几何先验。
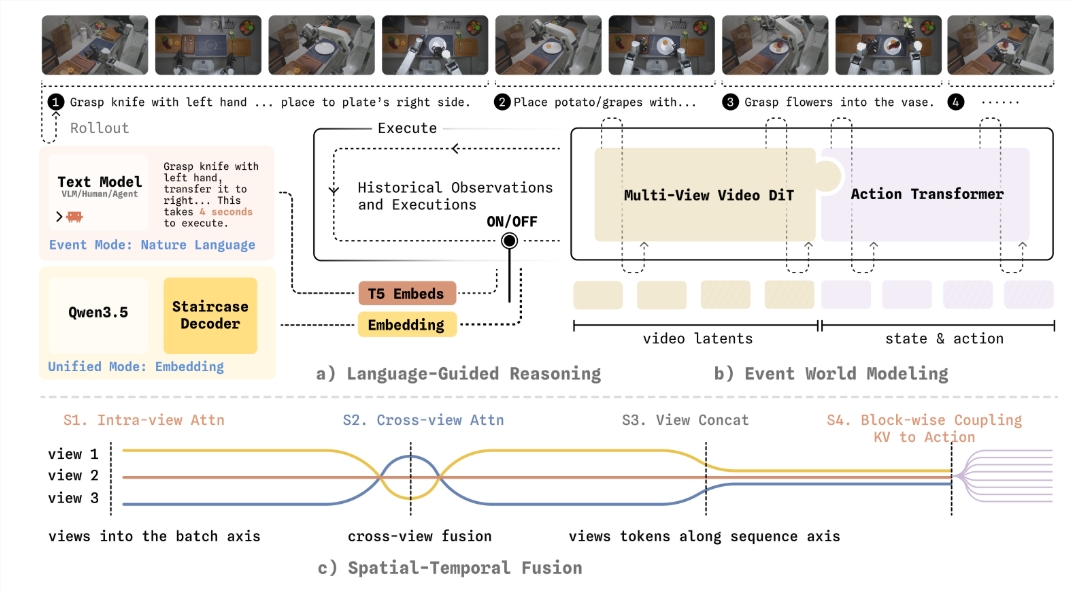
针对这一行业痛点,WALL-WM世界模型开创性地引入了“以事件为中心”的训练与执行机制。它将机器人的复杂任务根据动作边界切分为诸如伸手、抓取、移位等具有明确语义的事件关节。在实际运行中,模型不再死板地推算下一帧画面,而是先对“下一个事件会导致世界发生何种变化”进行超前预演,随后再将这种视觉变化精准翻译为机械臂的运动轨迹。
为了让这一全新架构在真实物理世界中稳定落地,自变量机器人团队进行了一系列的硬核工程重构。系统不仅支持在同一个基座权重下灵活切换变长动作输出的“事件模式”与实时闭环控制的“统一模式”,还实现了视频模型与动作模型的单向耦合分工生长,有效避免了互联网视频中宝贵的动态先验被动作数据过早带偏。此外,针对多摄像头设备的几何感知,模型引入了视锥掩码与管状掩码机制,强迫AI建立跨视角的真实三维几何对应能力;而在决策延迟问题上,则通过全新的“阶梯式思维链解码”技术,在保留逻辑可解释性的同时大幅降低了解码延迟。
从支撑该模型长出动作能力的“数据金字塔”来看,团队同样构建了极其严密的系统工程。底层依托百万级网络通用视频补足视觉先验,顶层则聚焦真机接管与纠错数据。配合四级层级化标注、双聚类采样、分布式“Muon”训练系统以及部署端的FP8量化,WALL-WM不仅在具身视频生成质量和三维空间感知等多项指标上全面领跑,更在真机Core15L1基准测试的泛化场景中取得了极为优秀的任务完成分数。目前,该项目的开源代码及主页已正式对外公开。
来源:Heooo AI工具导航