
MiniMax发布M3大模型,首创MSA架构并全面开源
「MiniMax推出M3大模型,首创MSA稀疏注意力架构,支持1M上下文,性能超越GPT-5.5,并全面开源。」
近日,人工智能领域迎来重大技术突破,MiniMax正式发布了其最新一代大模型——M3。该模型在底层架构上进行了颠覆性创新,自主研发了稀疏注意力架构(MSA),旨在解决复杂智能体任务中普遍存在的上下文扩展瓶颈。与传统的注意力机制相比,MSA架构通过更精确的KV分块与算子层优化,实现了计算速度的显著提升,较同类开源方案提升超过4倍。
M3模型的最大亮点之一是其对超长上下文的支持能力,原生支持高达1M的上下文长度。在如此庞大的上下文规模下,M3的每Token计算量仅为上一代模型的二十分之一至十分之一,预填阶段和解码阶段分别实现了超过9倍和15倍的加速。这一突破意味着开发者可以在不牺牲性能的前提下,处理海量文本、代码或多模态数据,为复杂应用场景提供了坚实基础。
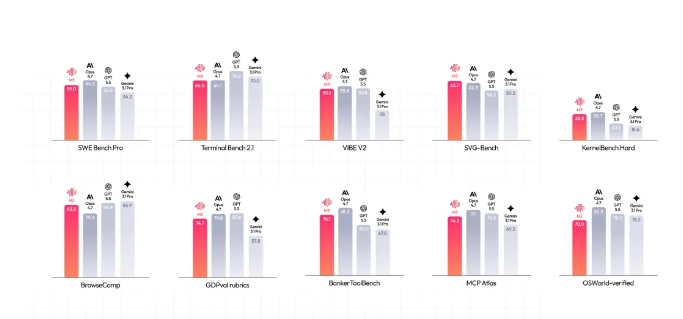
在性能方面,M3的表现同样令人瞩目。通过原生百万亿量级交错数据的混合训练,M3的语义空间实现了高度融合,在SWE-Bench Pro等软件工程及多模态权威评测中,其综合能力超越了GPT-5.5和Gemini 3.1 Pro等海外旗舰模型。更令人印象深刻的是,在极限任务实测中,M3展现出极强的长线程自主规划能力。它曾历时12小时自主复现ICLR顶级论文实验,更在无参考代码的情况下连续运行24小时,调用工具近两千次,成功将Hopper架构上的FP8矩阵乘硬件利用率从7.6%提升至71.3%。此外,M3还在开放式PostTrainBench中自主调度模型,完成了“数据-训练-迭代”的全流程,充分证明了其作为通用智能体基座的潜力。
伴随M3模型的发布,MiniMax还同步推出了专为长程复杂协作设计的MiniMax Code智能体产品,以及极具价格竞争力的Token Plan及API服务。MiniMax承诺在10天内开源模型权重,这一举措不仅打破了前沿多模态与长上下文技术由海外闭源模型垄断的格局,更以全要素开源的形式重塑了国内开发者生态的性价比边界。
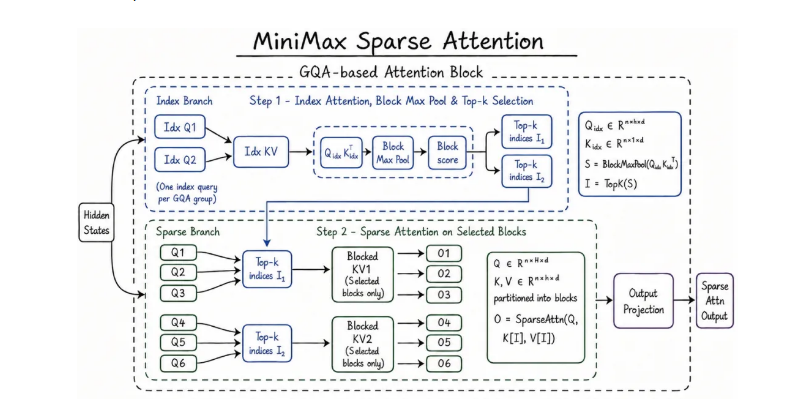
M3的发布标志着国产大模型在技术创新和开源生态建设上迈出了关键一步。其MSA架构的提出,为处理超长序列提供了全新思路,而全面开源策略则有望吸引全球开发者共同参与,推动AI技术的普惠化发展。对于行业而言,M3的出现不仅提升了国产模型在国际舞台上的竞争力,也为智能体、代码生成、多模态理解等前沿应用带来了更多可能性。
来源:Heooo AI工具导航