
Anthropic发布第五代Claude模型,编程与科学领域性能飞跃
「Anthropic推出第五代Claude系列模型Fable5和Mythos5,在编程、科学研究和网络安全等基准测试中取得领先成绩,同时引入全新安全降级机制。」
AI巨头Anthropic近日正式发布了第五代Claude系列的两款全新模型:面向通用市场的Claude Fable5,以及专注于特定专业领域的Claude Mythos5(现已结束预览阶段)。两款模型均基于同一基础模型构建,但在安全配置和应用场景上各有侧重,标志着AI技术在多个前沿领域的又一次重大突破。
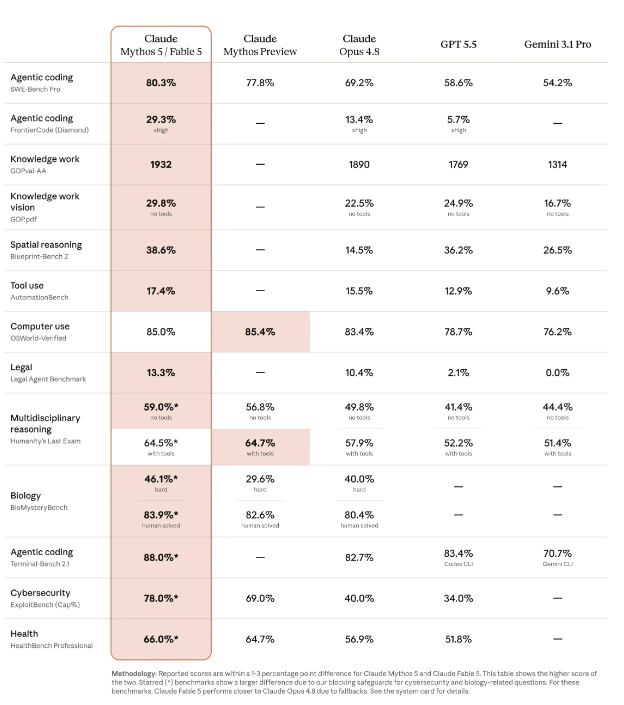
作为通用模型的Claude Fable5在几乎所有主流测试基准中都斩获了最高分,在长时间、复杂的任务处理中优势尤为显著。在软件工程领域,Fable5在评估无助状态下解决真实GitHub任务的SWE-Bench Pro测试中豪取80.3%的高分,远超Claude Opus4.8的69.2%和GPT5.5的58.6%。在更严苛的生产级编码基准FrontierCode上,它更是以29.3%的得分将GPT5.5的5.7%远远甩在身后。支付巨头Stripe表示,Fable5将原本需要5个月的工程工作缩短至几天;在一个拥有5000万行Ruby代码的代码库中,它仅用一天就完成了整个团队原本需要两个多月才能完成的迁移工作。
在知识工作与视觉方面,Fable5同样表现出色。它在金融分析(Hebbia基准测试)和图表解读上大获全胜,IMC交易集团表示该模型几乎全面通过了其交易分析评估。视觉方面,它能精准提取复杂的科学插图数据,并仅凭游戏截图就独立通关了《精灵宝可梦 火红》,完全脱离了前代模型所需的辅助框架。
与配备保守安全防护的Fable5不同,Claude Mythos5解除了网络安全等领域的限制,专门面向特定合作伙伴及美国政府(通过Project Glasswing项目)开放。在药物设计领域,Mythos5在无需人工干预的盲测中,能够自行选择结合位点、运行生物信息学工具并自我修复错误。在14个蛋白质靶点中,成功为9个产生了有效的候选药物,设计速度暴增10倍。Mythos5还成为首个能够提出科学假设的LLM:盲法对比显示,约80%的情况下科学家更倾向于Mythos5提出的分子生物学假设(例如大肠杆菌蛋白的新机制已被独立研究证实)。在自主基因组学研究中,Mythos5在无人工干预下连续工作超过一周,编译了138种动物、数百万个细胞的单细胞数据,并训练出自己的机器学习模型,其表现超越了《科学》杂志最近发表的模型,且体积缩小了100倍。在网络安全领域,Mythos5在ExploitBench基准测试中的得分从预览版的69%飙升至78%(Opus4.8仅为40%),被誉为“全球最强的网络安全模型”。
伴随强大性能而来的是成本的急剧攀升。Fable5和Mythos5的定价为每百万输入代币(MTok)10美元,每百万输出代币50美元,价格几乎是Claude Opus4.8的两倍。在Claude.ai的网页订阅计划中,新模型将按照2倍使用量计费。为了控制Mythos级别模型可能带来的风险,Anthropic在Fable5中内置了一套创新的分类器降级机制:只要检测到涉及网络安全、生物、化学或“提炼(模型能力提取)”的危险提示词,系统会自动将请求路由到较弱的Claude Opus4.8模型上(影响约不到5%的会话),并在界面上通知用户。针对旨在构建前沿大模型的提示词,系统不会直接拦截,而是会隐蔽地通过提示修改、引导向量或PEFT(参数高效微调)来“限制”其输出效果。在外部超过1000小时的测试中,测试人员未能找到通用的越狱方法,Fable5攻击任务的成功率为零。为此,Anthropic还增加了30天的数据保留期以检测新型攻击。
来源:Heooo AI工具导航