
阿里开源LOGOS模型打破科学语言壁垒
「阿里与人大联合开源LOGOS模型,通过统一Token序列编码蛋白质、小分子等异构对象,以超高效率和极低参数量实现跨学科科研范式重构。」
人工智能在科研领域的应用正迈向一个新的转折点。阿里 ATH-Token Foundry 联合中国人民大学高瓴人工智能学院正式宣布,开源了一款名为 LOGOS 的多模态科学大模型。这一模型旨在打破长期以来不同科学分支之间存在的“语言鸿沟”,让蛋白质、小分子以及复杂材料等异构科学对象能够通过统一的离散 Token 序列进行编码与交互。
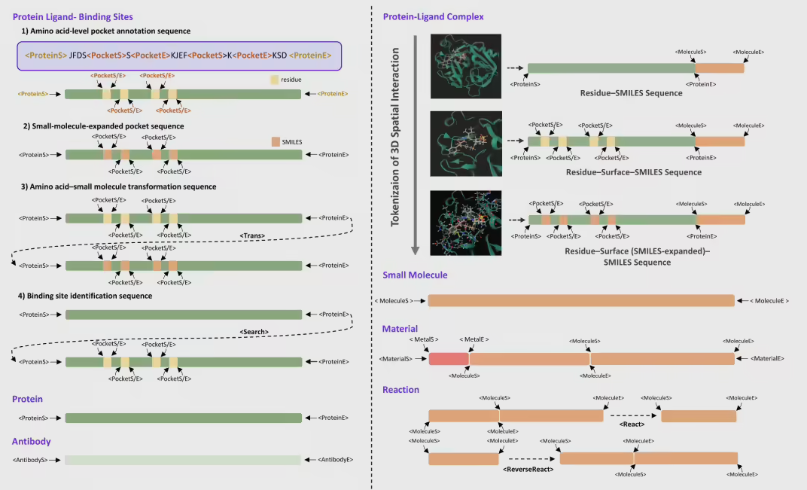
长期以来,不同科学分支之间存在着深不见底的“语言鸿沟”。蛋白质、小分子以及复杂材料,在AI眼中往往是结构迥异、难以兼容的数据孤岛。为了让这些科学对象能够“对话”,过去的研究往往需要依赖复杂的3D坐标或专门设计的几何神经网络,不仅计算成本高昂,且模型通用性极差,换一个研究环节就得重起炉灶。
LOGOS 的核心创新在于打破了这种壁垒。它设计了一套共享词表,将蛋白质、抗体、小分子及 MOF 材料等异构对象,通过统一的离散 Token 序列进行编码。这意味着,模型不再依赖昂贵的3D空间信息,而是通过类似“读文字”的序列预测方式,直接构建出复杂的3D空间互作规律。这种“科学语法”的建立,让不同学科的数据在底层实现了知识共享。
在参数效率上,LOGOS 展现出了惊人的表现。LOGOS-1B 版本仅用1/56的参数量,就在多项代表性科学任务中实现了对微软 NatureLM 的超越。此外,LOGOS 彻底解决了预训练与下游任务之间的“目标偏差”问题,使得模型无需繁琐的微调适配,即可直接激活生成能力,大幅降低了科研人员的开发门槛。
目前,LOGOS 已构建起包含7类模态、总计44.87B tokens 的超大规模预训练语料库。项目组已将相关模型权重、推理代码及详尽的技术报告全面开源,开发者可通过官方渠道获取并使用这一工具。这一突破性成果不仅为科研自动化提供了强力引擎,也为未来多模态科学大模型的开发树立了全新的技术范式。随着 LOGOS 的开源,科学界的“语言”或许将变得前所未有的统一与高效。
来源:Heooo AI工具导航