
学术团队仅用SFT登顶搜索智能体榜单
「学术团队发布OpenSeeker-v2,仅通过监督微调(SFT)技术,在搜索智能体榜单上超越工业巨头,实现首个纯学术SOTA。」
在大型语言模型(LLM)领域,深度搜索能力已成为衡量智能体性能的关键指标。然而,长期以来,这一赛道被资源雄厚的工业巨头所主导,传统开发模式依赖于极其消耗资源的流水线,包括预训练、持续预训练(CPT)、监督微调(SFT)以及强化学习(RL)。近日,来自学术界的研发团队打破了这一格局,发布了OpenSeeker-v2,仅凭SFT技术便登顶搜索智能体榜单,引发了业界的广泛关注。
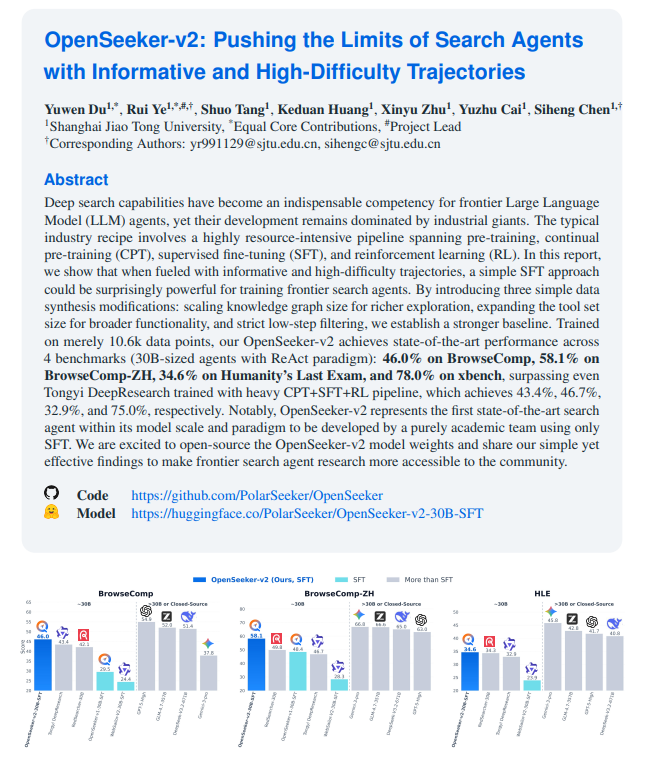
该团队在数据合成方面提出了三项核心优化策略,显著提升了模型的搜索能力。首先,他们扩大了知识图谱的规模,为模型提供了更丰富的探索空间,使其能够在更广泛的领域中进行有效搜索。其次,团队显著增加了工具集的数量,扩展了模型的功能边界,使其能够处理更多样化的搜索任务。最后,他们实施了严格的低步数过滤,确保训练数据的精炼与高效,避免了冗余信息的干扰。
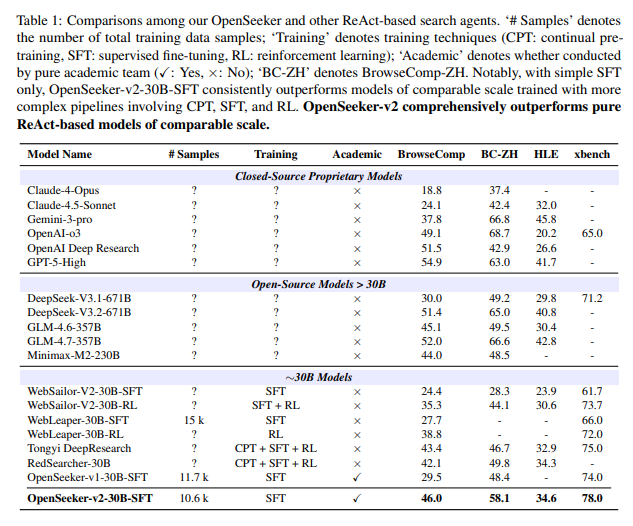
实验数据显示,OpenSeeker-v2仅基于1.06万条数据点进行训练,便取得了令人瞩目的成绩。在多个基准测试中,该模型在同等模型规模与架构下,超越了包括工业巨头在内的众多竞争对手,首次实现了由纯学术团队通过SFT技术达到的state-of-the-art(SOTA)水平。这一成果不仅证明了数据优化策略的有效性,也展示了学术界在资源有限的情况下,仍能通过技术创新取得突破。
值得关注的是,这是首个在同等模型规模与架构下,由纯学术团队仅通过SFT技术实现的SOTA搜索智能体。传统上,工业巨头凭借其强大的计算资源和数据积累,在搜索智能体领域占据主导地位。然而,OpenSeeker-v2的成功表明,通过精心设计的数据合成策略和高效的训练方法,学术界同样可以在这个领域取得领先地位。这不仅为学术研究提供了新的方向,也为资源有限的团队提供了可借鉴的经验。
目前,该团队已正式开源OpenSeeker-v2的相关代码和模型,供全球研究者和开发者使用。开源地址和论文链接已在官方渠道发布,论文详细介绍了数据合成优化策略和实验细节。这一举措将进一步推动搜索智能体技术的发展,促进学术界和工业界的合作与交流。
OpenSeeker-v2的发布,不仅是对现有搜索智能体技术的一次重要补充,也为未来的研究提供了新的思路。随着更多学术团队和开源社区的参与,搜索智能体领域有望迎来更多的创新和突破。未来,我们或许会看到更多基于SFT等高效方法的智能体模型,打破资源垄断,推动AI技术的民主化进程。
来源:Heooo AI工具导航