

Unsloth与NVIDIA合作提升LLM训练速度25%
「Unsloth与NVIDIA合作,通过优化元数据缓存和并行化数据复制,消除隐藏瓶颈,将GPU训练速度提升约25%。」
大语言模型(LLM)的微调是当前计算最密集的任务之一,持续挑战着硬件的极限。NVIDIA GPU专为这类负载设计,能够将复杂问题分解并并行处理。Unsloth作为一款流行的LLM训练优化工具,覆盖从本地RTX笔记本到DGX Spark个人AI超级计算机的广泛NVIDIA GPU产品线。为了帮助开发者充分发挥GPU潜力,Unsloth与NVIDIA合作,识别并消除了训练过程中隐藏的瓶颈,通过一系列新实现的优化,将GPU训练速度整体提升了约25%。
在优化模型训练时,开发者通常会首先关注高影响力的核心操作,如矩阵乘法(matmuls)、注意力机制、融合算子、分组通用矩阵乘法(grouped GEMM)等。这些核心操作承担了大部分算术运算,但当主要组件优化到位后,另一类瓶颈会浮现出来:GPU在依赖元数据的工作上出现停滞。运行时在每个迭代中重复构建相同的数据结构,而复制/计算流在原本可以重叠的情况下却按顺序执行。
针对这些瓶颈,Unsloth与NVIDIA合作实现了三项关键改进:argsort、bincount以及packed-sequence caching(序列打包缓存)。这些优化的共同模式非常简单:减少重复的簿记工作,让复制操作与有用的计算并行进行。
具体来说,在训练过程中,为了处理不同长度的序列,传统做法是将所有序列填充到相同长度,这会导致大量计算浪费在填充标记上。而Unsloth采用序列打包技术,将多个短序列拼接成一个更长的打包序列,从而消除填充浪费。但模型仍需要知道每个原始序列的起始和结束位置,因此需要携带序列元数据,如cu_seqlens(累积序列长度)、max_seqlen(最大序列长度)以及掩码结构。对于固定的打包批次,这些元数据在每个层(layer)都是相同的。

如果模型有L层,那么在每层中重新构建或重新同步这些元数据,并不是新的工作,而是反复重建相同的信息。理想情况是:构建一次元数据,在L层中重复使用。而浪费的做法是:在每层都重复构建。这种开销主要不是额外的浮点运算,而是某些路径会强制设备到主机的同步,形成GPU-CPU同步点。一旦同步发生在每层路径中,开销就会在每层重复出现。
序列打包缓存优化正是为了解决这个问题。它不再在每层反复重建打包序列信息、SDPA打包掩码和xFormers块掩码,而是将这些可重用的元数据以及从元数据派生的注意力侧结构缓存到每个设备上,供当前打包批次使用。这些缓存的结构随后在层之间重复利用。
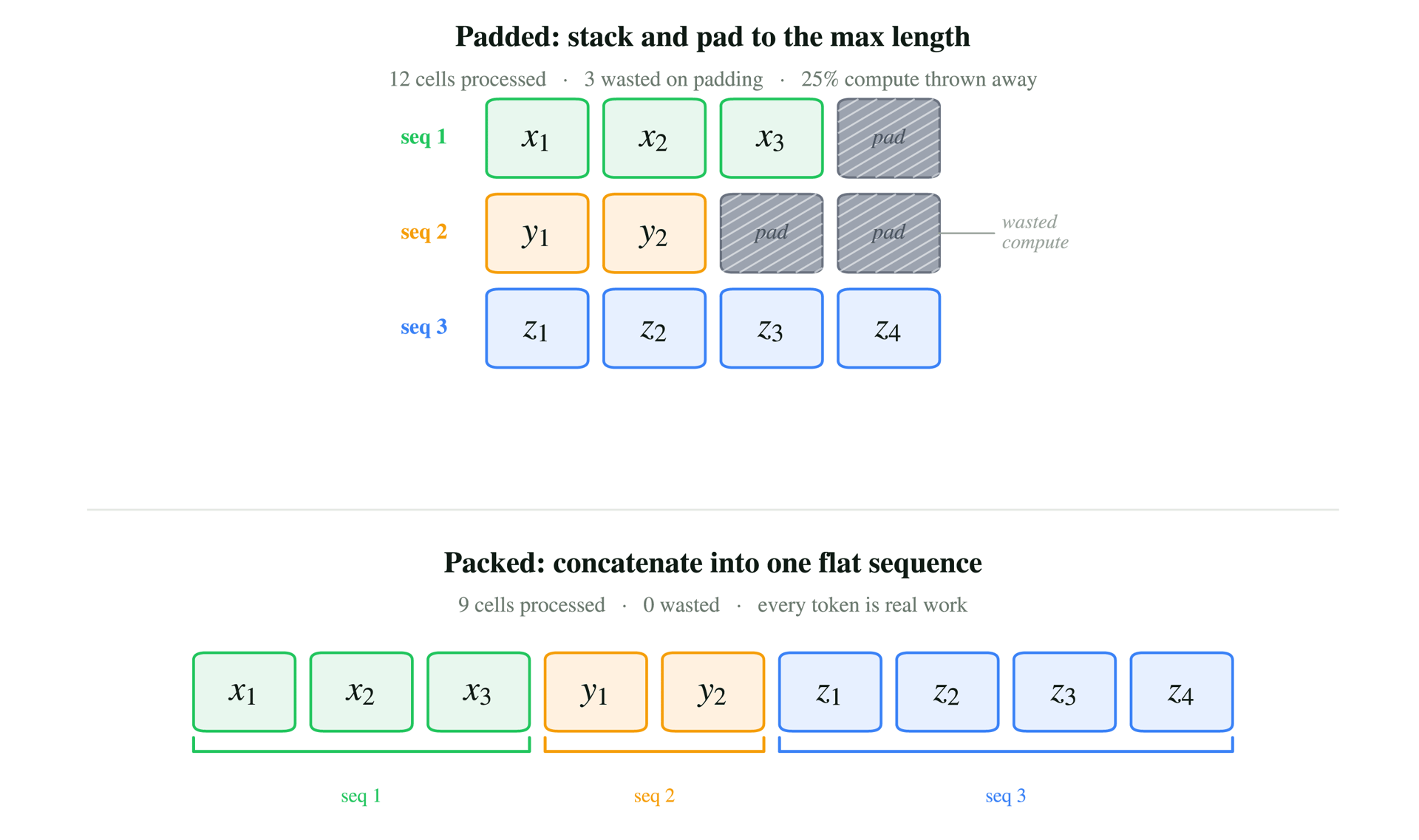
打包训练本身已经通过消除填充浪费提高了利用率,但如果元数据路径不断强制同步,部分收益就会损失在重复开销中。Unsloth的缓存机制有效避免了这种同步,使得GPU能够更高效地执行计算。此外,argsort和bincount的优化进一步减少了不必要的排序和计数操作,使计算流更加平滑。
这些改进共同带来了约25%的训练速度提升,对于需要大量迭代的LLM微调任务来说,这意味着显著的时间节省和成本降低。开发者可以在不牺牲模型质量的前提下,更快地迭代实验、调整超参数或部署新模型。
Unsloth表示,这一合作成果已经集成到其开源工具中,开发者可以直接使用。随着LLM应用日益普及,训练效率的优化将成为推动AI民主化的重要力量,让更多开发者能够在有限的硬件资源上探索大模型的潜力。
来源:Heooo AI工具导航